簡介碩班的研究
- 一言以蔽之:「利用深度學習的模型做語音辨識的任務」
- 參考:
語音辨識(Automatic speech recognition, ASR)是一個 Sequence-to-sequence 的任務,將輸入的語音訊號轉換為相對應的文字輸出,是一個日常上很常見的應用,而我的目的就是設計出一個模型,使得辨識的錯誤率越低越好。當然,一個模型的好壞不只是單看錯誤率,也要看這個模型的辨識速度(每秒可以處理多長的音訊)以及模型大小(參數量)。

一個語音辨識器的困難點在於需要學習到兩個模態(語音、文字)之間的關係,不僅要從多變的語音訊號中抽取出相對應的特徵,而且要能夠根據上下文的語意選擇精準的文字,以中文語音辨識來說,模型有能力辨識出發音,但常會有同音錯字的形況發生(e.g. 這座程式很美、鋼材你有說話嗎、中國剛才的價格走勢)。

動機
我在 ASR 研究出發點圍繞在以下的問題:
- Non-autoregressive 方法辨識速度很快,CTC 的問題是條件獨立假設在理論上沒辦法學習到上下文的關係,如何增強 NAR 模型學習到語意的資訊呢(緩解 Conditional independence assumption)?
- 要怎麼將 Pre-trained LM(BERT) 整合進 ASR 模型當中?同時又不能讓整個模型因為 pre-trained model 變得太龐大
Auto-regressive vs. Non-autoregressive manner
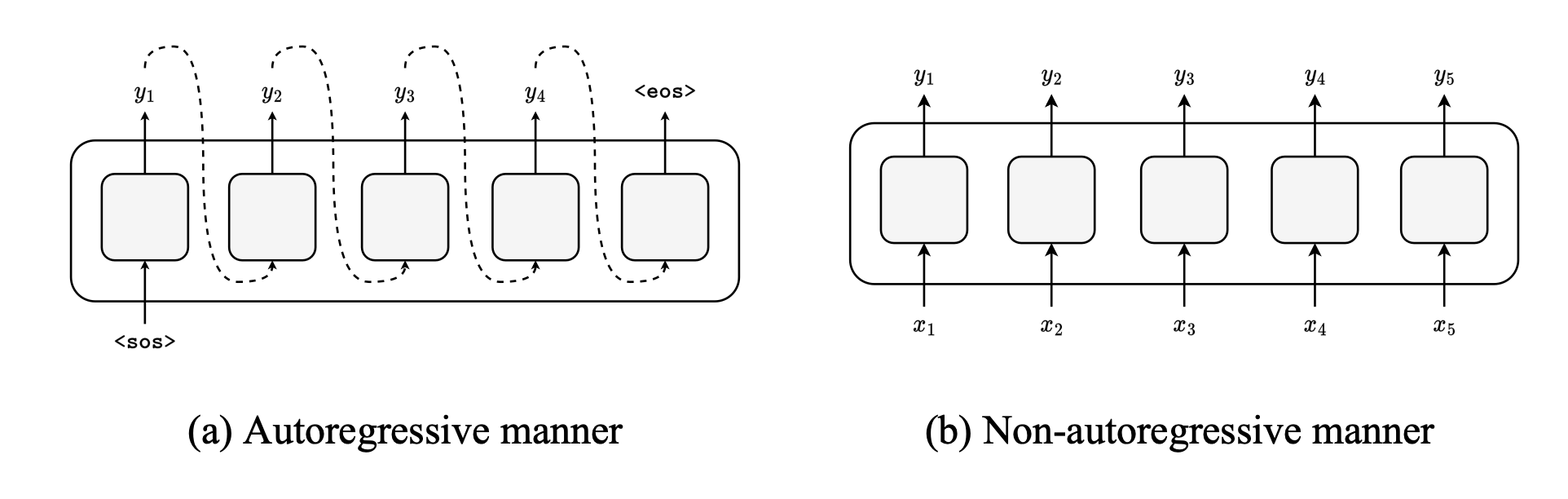
我們可以根據 deocoding 的方式將 End-to-end ASR 模型分為兩個系列:Autoregressive(AR) 和 Non-autoregressive(NAR)。AR 模型是基於先前已經產生出來的結果去生成下一個字(e.g. 今天天氣很 -> 好),其優點是可以較好的抓到文字語意上的關係,但為了一個一個字生成,會導致辨識的速度比較慢。另一方面,NAR 模型則是一次產生出整個句子,在辨識速度上可以比 AR 模型快 5~50倍,但因為要「一次產生」,所以必須假設每個輸出之間是條件獨立的(Conditional independence assumption),使得這類的模型會難以捕捉句子上下文的資訊,導致辨識的錯誤率更高(更常選錯字)。
- Autoregressive:基於已生成的結果,產生出下一個字
- 優點:
- 因為在 decode 時有參考到先前輸出的文字的資訊,所以 error rate 比較低(比較好抓文字的資訊)
- 缺點:
- 需要 L 次辨識才能輸出 L 個字,比較慢
- 優點:
- Non-autoregressive:一次辨識出所有字(平行的輸出)
- 優點:
- 速度很快(可以到 AR 的 5 倍到 50 倍快)
- 缺點:
- 錯誤率較高
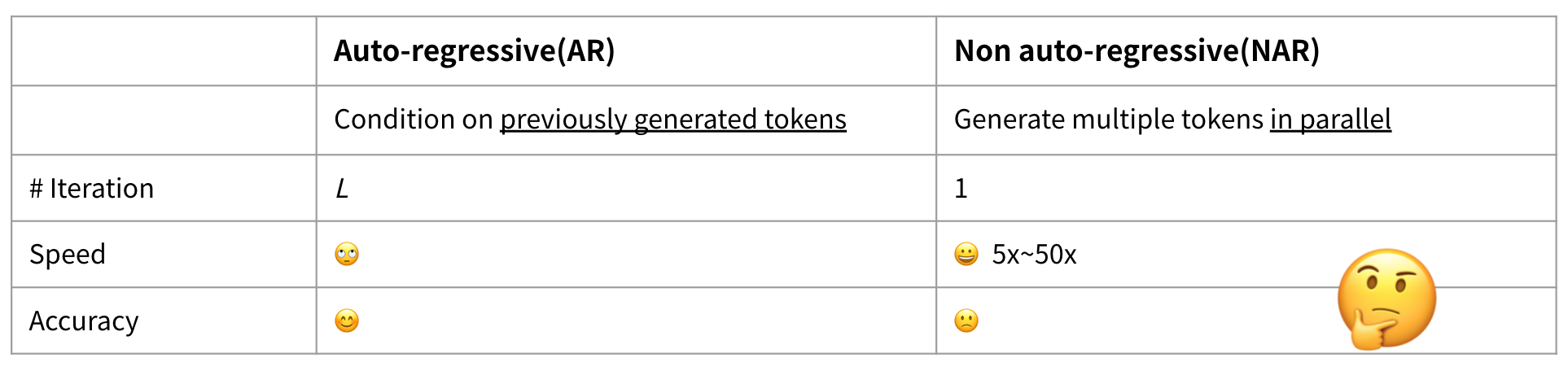 在一開始 AR 模型是主流的研究方向,但由於 Attention-based 的架構越來越成熟之後,NAR 的模型也開始是很重要的研究主題,原因是因為可以透過架構本身去更好的捕捉上下文的資訊 (2021 - Recent Advances in End-to-End Automatic Speech Recognition)。
在一開始 AR 模型是主流的研究方向,但由於 Attention-based 的架構越來越成熟之後,NAR 的模型也開始是很重要的研究主題,原因是因為可以透過架構本身去更好的捕捉上下文的資訊 (2021 - Recent Advances in End-to-End Automatic Speech Recognition)。
- 錯誤率較高
- 優點:
在 NAR ASR 的研究中主要要解決幾個問題:
- 輸出的長度不確定
- 因為 Conditional independence assumption,所以我們無法知道輸出到底要有幾個字
- 常見的作法為 CTC, LASO, CIF...等
- 條件獨立假設
- 缺少上下文的資訊
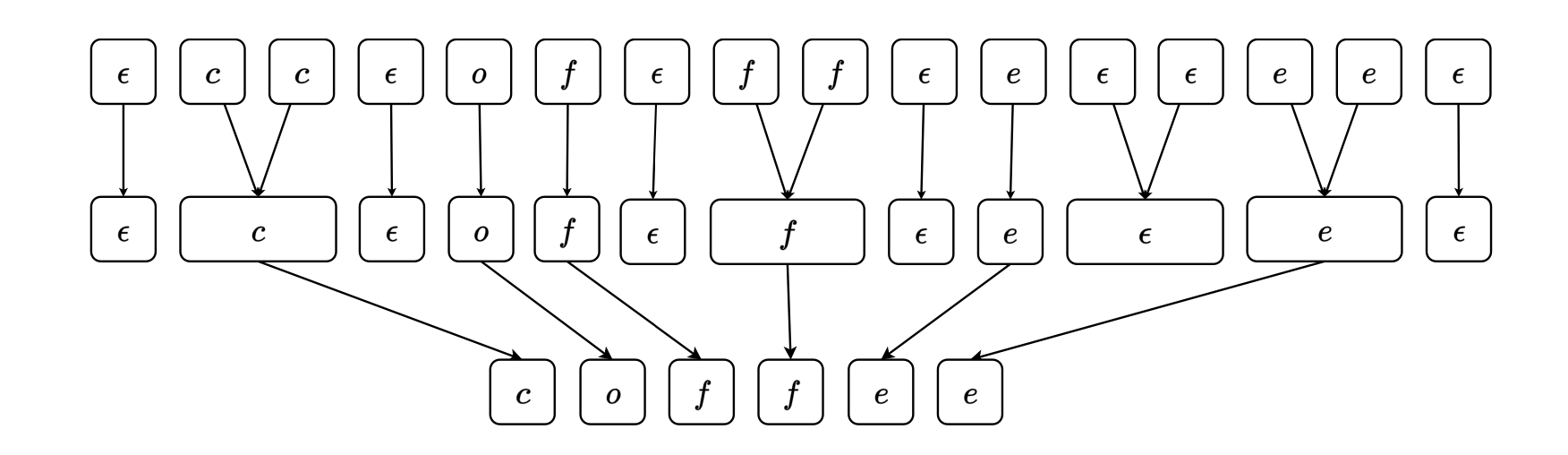
CTC
由於在語音辨識中,輸入的語音序列的長度會大於文字序列,所以可以在輸出的文字序列插入「blank token」(代表沒有輸出),再經過簡單的後處理得到最後的句子。具體上來說就是將辨識出來的序列經過一個 collapse function(,先合併重複的 token ,再去掉 blank token)。
Integrating Pre-trained Models into ASR
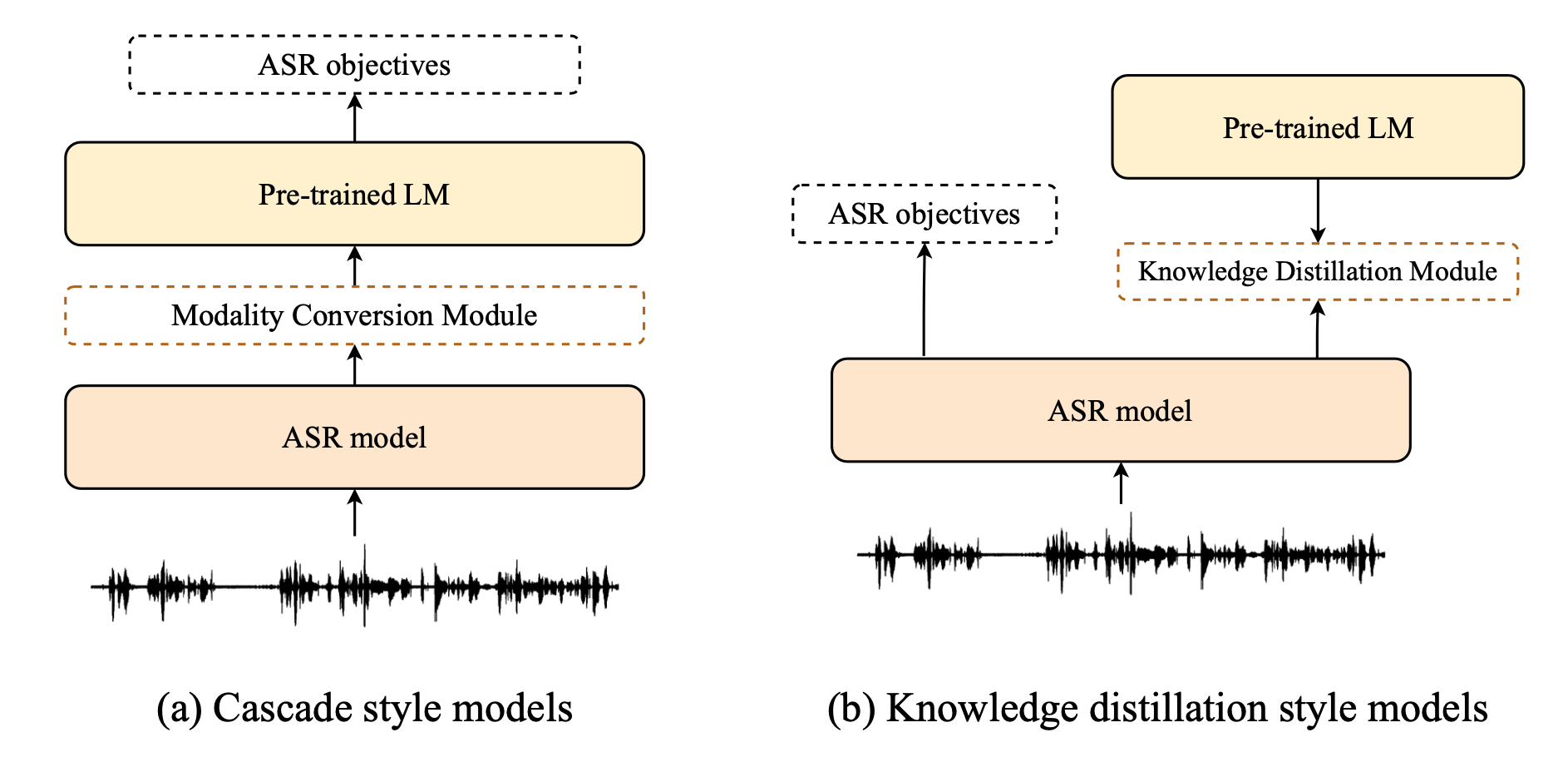
另一個方面,因為 self-supervised pre-trained model 在近幾年變成顯學,語音和文字分別都已經有很多 pre-trained model。這類的模型是預訓練在龐大的 unlabeled 學習到通用的資訊,在使用時只需要少量跟任務有關的 data 就能應用到下游任務上。而我的目標則是將, BERT(文字) 和 wav2vec2.0(語音),兩個 pre-trained model 結合進 ASR 系統中。有許多研究已經提出了很多方法將 Pre-trained model 整合進 ASR 系統中,大致上可以分為兩個類別:Cascade style 與 Knowledge distillation style。
Casacde style 方法是將 Pre-trained language model 納入 ASR 系統的一部分,這類方法假設文字的知識已經存在於��模型參數當中,我們可以用 ASR 的資料直接 fine-tune 整個模型,但這類的方法的問題是:
- 參數量太大
- Pre-trained model 通常都有非常大的參數量,將會使 ASR 系統變得太大、太難訓練
- Catastrophic forgetting problem
- 由於語音和文字仍存在不同,所以直接將 Pre-trained LM 用 ASR 的方式訓練,可能使模型忘記之前學過的東西
- 需要設計 Modality conversion module 來轉換兩個模態的差異
Knowledge distiallation style 方法則是讓 ASR 模型以 teacher-student 的方式,在訓練時學習 Pre-trained language model 產生的特徵(例如:distribution, attention weight...),而在測試時則不需要 Pre-trained model 的協助。這類模型的優點是可以降低測試時的參數量,達到更快的辨識速度,但其缺點是需要去決定「到底要學習怎樣的特徵?」。舉例來說,從以前的研究可以得知 BERT 在不同層學習到不同粒度的資訊,但我們很難從理論上來得知究竟怎樣的資訊是對一個 ASR 系統有幫助的?