📎End-to-End Speech Recognition by Following my Development History - Guest Lecturer Shinji Watanabe
以前的筆記
Impression in ~2015!
- Attention based encoder decoder
- No conditional independence assumption
- Attention mechanism allows too flexible alignments(太難train)
Implementation 2016
CTC
- Relying on conditional independent assumptions(similar to HMM)
- Output sequence is not well modeled(no LM) LAS
- Attention allows too flexible alignments
- Too hard to train from scratch
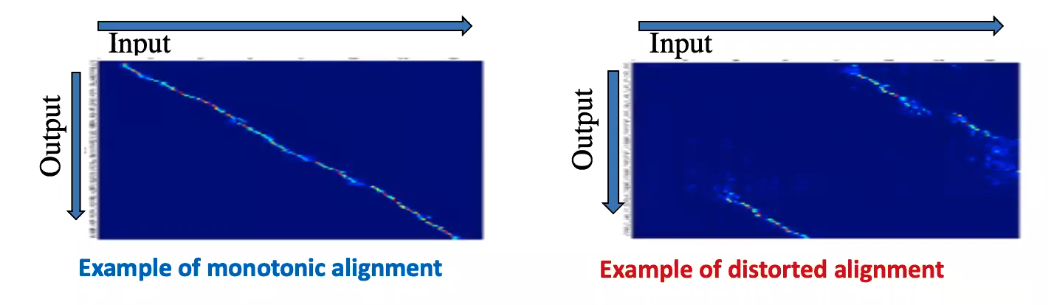
Input/output Alignment desired ASR system is monotonic (一條線) 但 End-to-end train 的模型很難是一條線
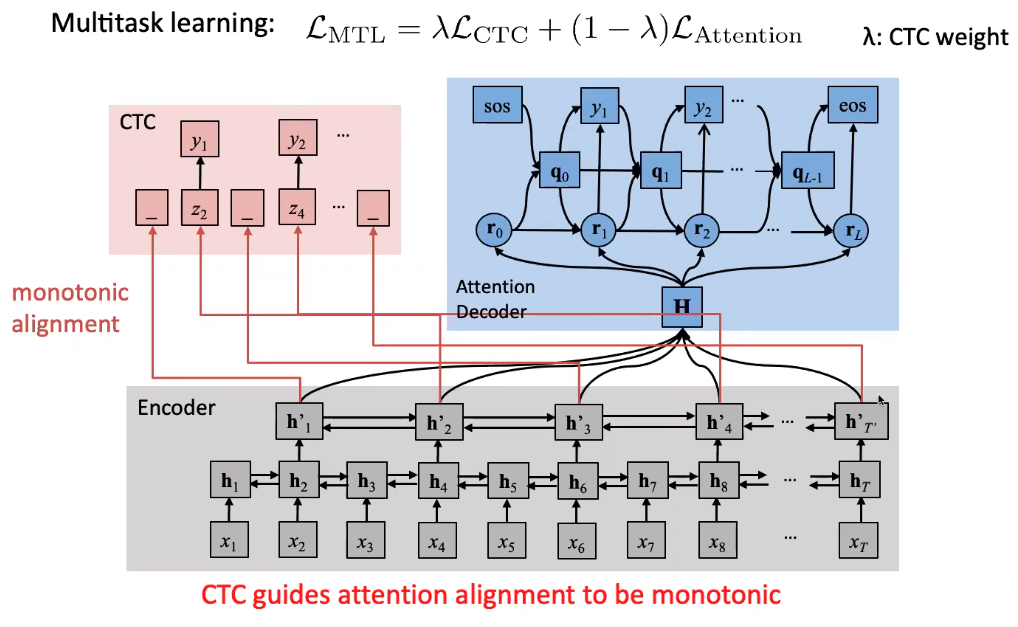
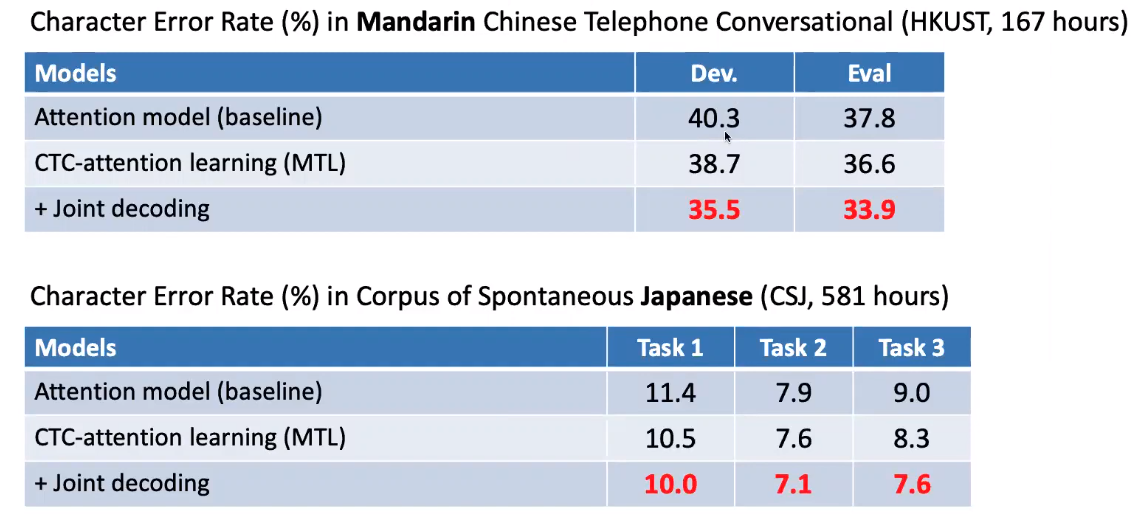
Use both benefits of CTC and attention
Hybrid CTC/Attention network working well!
- Attention based 的模型要 train 起來要花太多時間才能收斂,其平行訓練帶來的好處其實沒有比 RNN 多。
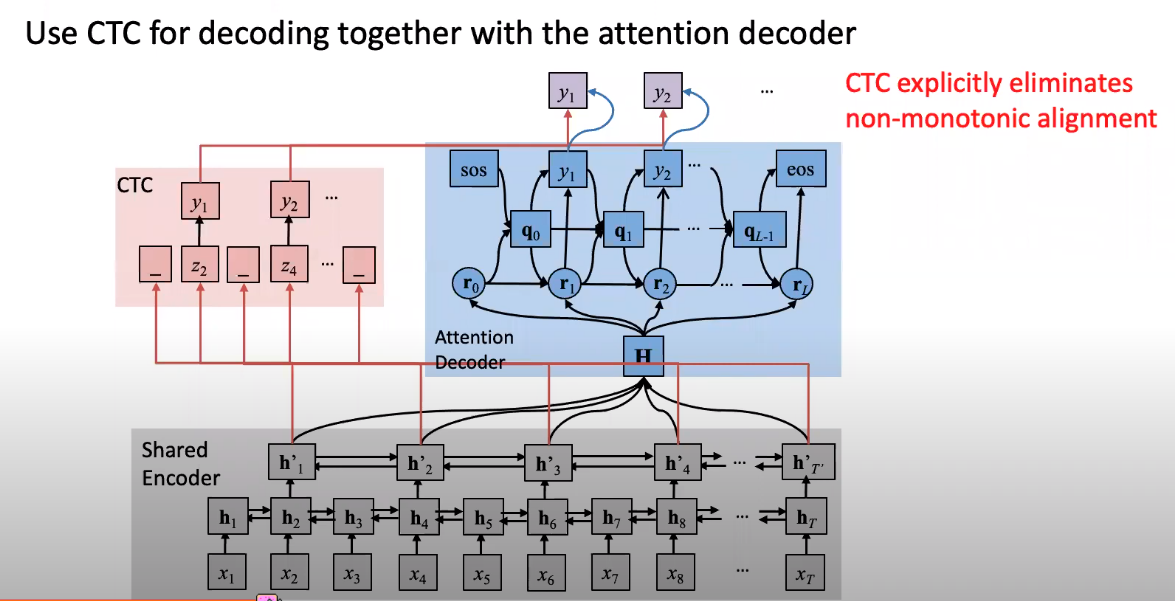
+ joint decoding
Discussions

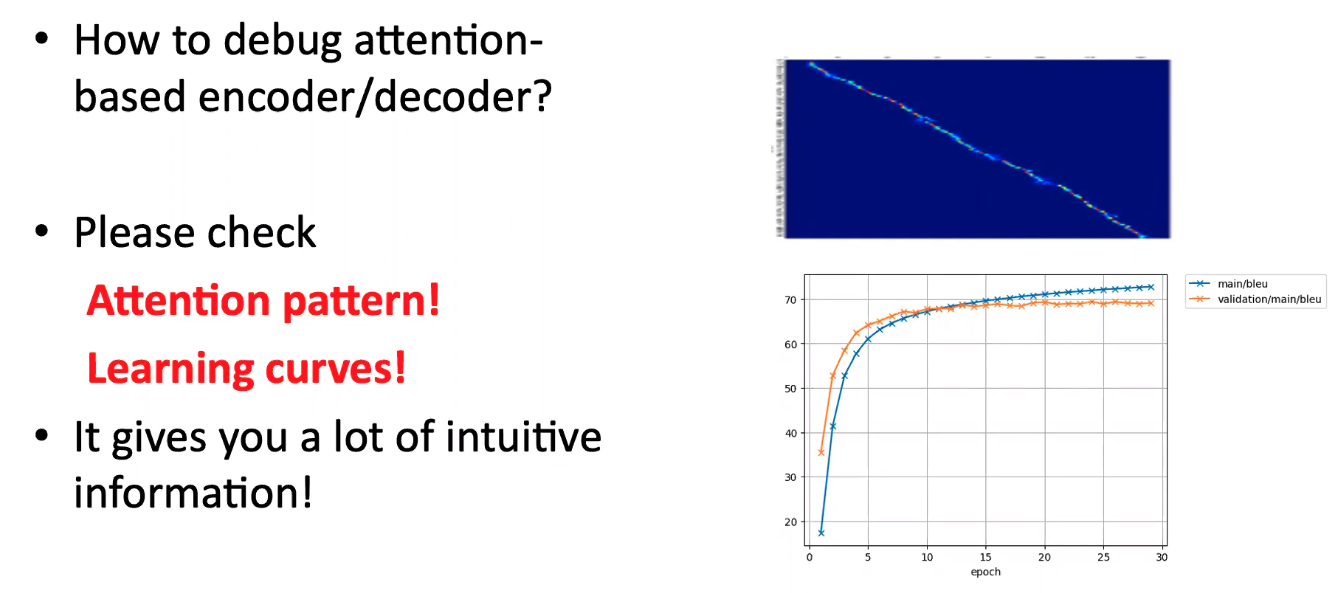
Check
- Attention pattern!
- Learning curves!
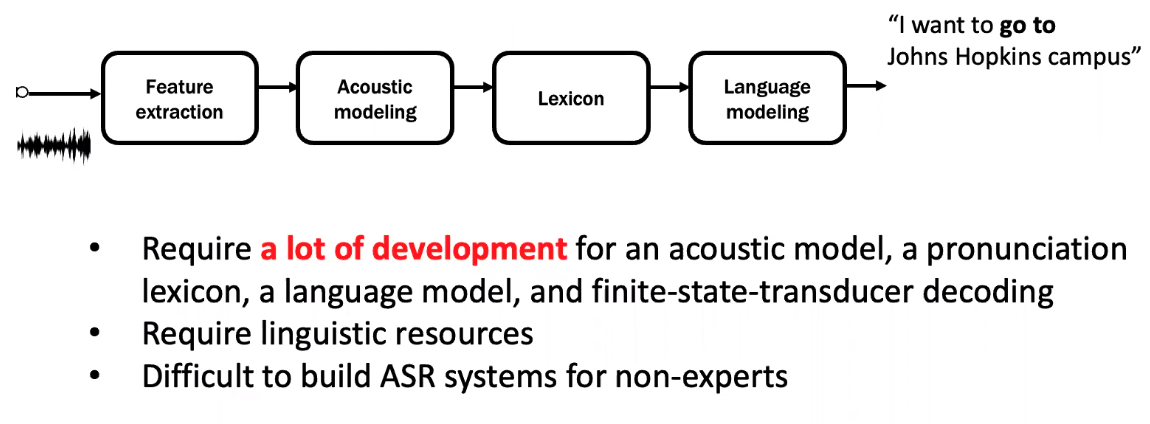
Speech recognition pipeline
傳統的 pipeline: 太多獨立假設才能解